ブログ
「検索エンジン最適化(SEO)スターター ガイド」をきちんとやってみた
2019.06.14
弊社ウェブサイトのリニューアルに際して、Googleが公開している「検索エンジン最適化(SEO)スターター ガイド」をきちんとやってみた記録の一部です。
新しくウェブサイトを制作したり、リニューアルされた際には、ぜひ参考にしてください。
目次
この記事では、前半部分を投稿しています。
- はじめに
- Google がコンテンツを見つけられるようにする
- クロール対象外のページを Google に指示する
- Google(とユーザー)がコンテンツを理解できるようにする
- Google 検索結果での表示を管理する
- サイトの階層を整理する
- コンテンツを最適化する
- 画像を最適化する
- サイトをモバイル フレンドリーにする
- ウェブサイトを宣伝する
- 検索のパフォーマンスとユーザーの行動を分析する
検索エンジンにヒットさせて自社サイトや自社サービスを検索結果の上位に表示されるようにしたいものですね。
今回は、検索エンジンのスタンダード的な立ち位置にあるGoogle自身が公開している「検索エンジン最適化(SEO)スターター ガイド」に従って、重要なポイントを漏れなくおこなってみました。
このガイドは、Googleの検索エンジンを効果的に利用することを主眼に書かれており、Google側の仕様変更などの都度、内容が更新されています。
検索エンジン最適化(SEO)スターター ガイド
https://support.google.com/webmasters/answer/7451184?hl=ja
それでは、検索エンジン最適化(SEO)スターター ガイド(以下、スターターガイド)の目次の項目に沿って進めていきましょう。
1.はじめに
以下の内容では、スターターガイド冒頭の「用語集」に基づいて記載しています。
用語がわからない場合には、スターターガイドを確認してみてください。
まずは、現在の検索エンジンの登録状況を確認します。
「site:」を付けてサイトのホームページの URL を検索し、インデックスに登録されているかを確認します。
新規ドメインでまだコンテンツがなかったり、アップロードしたばかりで、検索結果が表示されていない場合には、次のステップで登録していきます。
また、他の人・組織が使用していたドメインを取得した後で使用する場合で、検索結果に何か出てくる場合には、その内容に注意した方がよいでしょう。
2.Google がコンテンツを見つけられるようにする
Googleの「クローラ」にページを見つけてもらうのも1つの方法ですが、何日も時間がかかる場合や、外部からのリンク数が少なくて見つけてもらえないことがあります。
そこで、サイトマップを作成して、こちらからGoogleに知らせることができるようになっています。
次のような所定の形式のファイルを用意する必要して、それをGoogle Search Console から送信するだけです。
XMLやテキストが対応しやすいのではないかと思います。
対応しているファイル形式
- XML
- RSS, mRSS, Atom1.0
- テキスト
- Googleサイト
サイトマップについて
https://support.google.com/webmasters/answer/156184
- Google Search Console にアクセスします
- Googleアカウントでログインしている場合は、「今すぐ開始」ボタンを押します。ログインしていない場合は、先にアカウントを登録してください。
-
「Google Search Consoleへようこそ」画面で、Googleに知らせたいウェブサイトの「プロパティ」を作成します。
2種類の作成方法がありますが、「URLプレフィックス」の方に、「https://」や「http://」で始まるウェブサイトのURLを入力する方が簡単です(DNSの確認が不要なため)。 - 「続行」ボタンを押すと、確認されます。
弊社の場合は、すでにGoogle Analyticsのサービスを利用中でしたので、そちらを根拠に確認したとメッセージが表示されました。 - XMLファイルをサーバーにアップロードします。
- 引き続き、プロパティー内の画面で、左サイドメニューの「サイトマップ」を選択して、アップロードしたXMLファイルのURLを入力して「送信」ボタンを押しました。
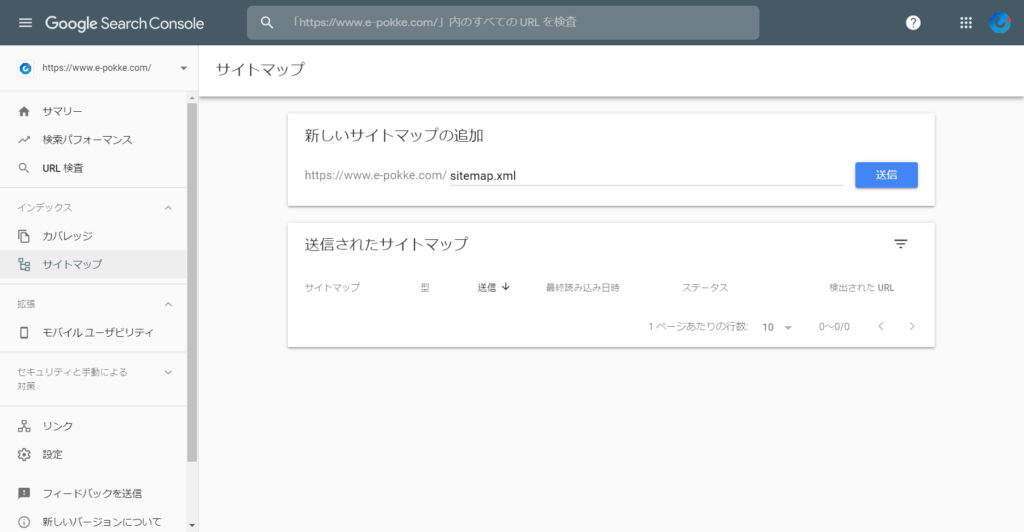
- 正常に送信され、URLの抽出が完了すると、「送信されたサイトマップ」欄に「成功しました」とメッセージが表示されます。

3.クロール対象外のページを Google に指示する
ウェブサイト上には、積極的に公開したくないURLもあるでしょう。
例えば、特定の広告ページからのみリンクして欲しい「ランディングページ」などです。
こうした場合に備えて、クロールの対象外にしたいページをクロールに知らせることができる仕組みがあります。
robots.txt ファイルについて
https://support.google.com/webmasters/answer/6062608
そのため、機密事項をサーバー上においた状態でrobots.txtで対象外にしてしても、機密は保持されませんのでご注意ください。
機密事項を掲載するページについては、別の方法でアクセス制限をするか、サーバーの公開領域にアップロードしないようにします。
次の内容のテキストファイルを作成して、サーバーのドキュメントルート(公開領域の最上位の階層)にアップロードしました。
現時点では、クロールの対象外にしたいページが特になかったので、エラードキュメント(何らかのエラーが発生したときに表示されるページ)が格納されたディレクトリを指定しています。
また、サイトマップの場所についても指定してみました。
User-agent: * Disallow: /errdocs/ Sitemap: https://www.e-pokke.com/sitemap.xml
4.Google(とユーザー)がコンテンツを理解できるようにする
ウェブサイトのページは、HTMLをもとに、画像や動画、CSS、Javascriptなど様々なファイルから構成されています。
その昔、クローラーが発達途中の頃は、HTMLだけを読み込んで処理しており、逆にそれを利用して検索エンジン対策がとられていたこともありました。
検索エンジンの究極の目標は、人にとって検索しやすい結果を提示することですが、HTMLだけの読み込みでは分からないことが多くありました。
現在は、人がブラウザからアクセスしたのと同様に様々なファイルをきちんと読み込み、適切なインデックスを作っていけるようになっています。
以下のツールを使用することで、クローラーがどのようにコンテンツを認識するのかを確認できます。
URL 検査ツール
https://support.google.com/webmasters/answer/9012289
Google Search Consoleでは様々な検査ができますが、今回は、次の検査を行いました。
- インデックス登録された URL の検査
- 公開 URL の検査
- Google Search Console にアクセスします
- 検査したいウェブサイトの「プロパティ」を選択し、左サイドメニューにある「URL検索」リンクを押します。
-
検査対象のURLとして、「https://www.e-pokke.com/」を入力してリターンキーを押すと、検査結果が表示されました。
ここにいろいろなURLを入力して、ページごとに検査結果を詳細に確認できる仕組みです。
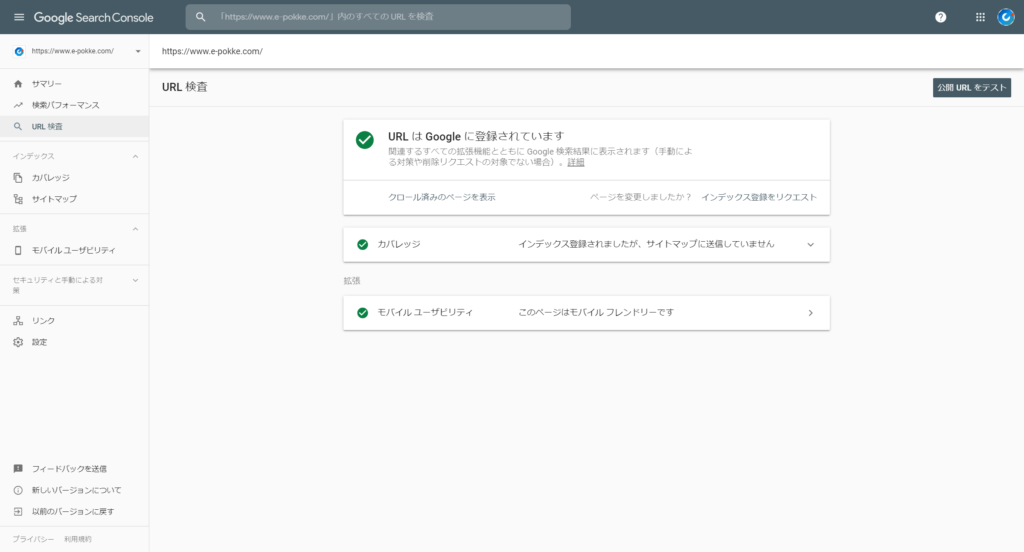
-
引き続き、画面右上の「公開URLをテスト」ボタンを押します。
これは、Googleに保存しているインデックスを参照するのではなく、実際のサーバー上のファイルにアクセスしてテストしますので、まだクローラーが調べていない状態のページについても検査できます。 -
検査結果として、「テスト済みのページを表示」をクリックすると、HTMLソースや、クローラーがどのような画面として見えているかのスクリーンショット、その他の情報を確認できます。
ただ、「その他の情報」では、アクセスできるはずのCSSファイルなど一部で「リソースを読み込めませんでした」と表示されていまい、原因が分かりません。

ここまで、「検索エンジン最適化(SEO)スターター ガイド」の前半部分を進めてきました。
後半部分は、また改めて進めてみたいと思います。
以上、お役に立てれば幸いです。
